SQL Server triggers are special stored procedures that are intended to run automatically in response to specific database events. These events could include activities related to data definition, like CREATE, ALTER, or DROP, as well as actions related to data manipulation, like INSERT, UPDATE, or DELETE. There are two main categories of triggers.
- DML Triggers (Data Manipulation Language Triggers): These triggers activate in response to DML events, which encompass operations like INSERT, UPDATE, or DELETE.
- DDL Triggers (Data Definition Language Triggers): These triggers activate in response to DDL events, which include operations such as CREATE, ALTER, or DROP.
When Is a Trigger Useful?
In a variety of situations, triggers are employed to guarantee that particular actions are carried out automatically in reaction to particular database events. Here are a few such scenarios when triggers are useful.
- Audit Trails
- When: You need to track changes to important data for compliance, security, or historical analysis.
- Why: Triggers can automatically log changes to an audit table without requiring additional application code, ensuring consistent and reliable tracking.
- Enforcing Business Rules
- When: Business rules must be enforced directly at the database level to ensure data integrity and consistency.
- Why: Triggers ensure that business rules are applied uniformly, even if data is modified directly through SQL queries rather than through an application.
- Maintaining Referential Integrity
- When: You need to ensure that relationships between tables remain consistent, such as cascading updates or deletes.
- Why: Triggers can automatically handle referential integrity tasks, reducing the risk of orphaned records or inconsistent data.
- Synchronizing Tables
- When: You need to keep multiple tables synchronized, such as maintaining a denormalized table or a summary table.
- Why: Triggers can automatically propagate changes from one table to another, ensuring data consistency without manual intervention.
- Complex Validations
- When: Data validation rules are too complex to be implemented using standard constraints.
- Why: Triggers can perform intricate checks and validations on data before it is committed to the database.
- Preventing Invalid Transactions
- When: Certain operations should be blocked if they don't meet specific criteria.
- Why: Triggers can roll back transactions that violate predefined conditions, ensuring that only valid data modifications are allowed.
Benefits of Triggers
Automated Execution: Triggers execute automatically in response to particular events, reducing the necessity for manual interference.
Centralized Logic: Business regulations and data integrity checks can be centralized within triggers, enhancing system maintainability and reducing code repetition.
Real-time Auditing: Triggers can be utilized to generate real-time audit logs of data alterations.
Complex Integrity Checks: Triggers can enforce complex integrity checks that surpass the capabilities of standard SQL constraints.
Data Uniformity: Triggers aid in upholding data uniformity by ensuring that associated modifications are implemented throughout the database.
Special tables and SQL Server Triggers
The "magic tables" of SQL Server are two unique internal tables: DELETED and INSERTED. These tables are used by DML triggers to hold the data that is being changed by the action that initiates the trigger.
Comprehending Tables—INSERT AND DELETED
- The INSERTED table stores the affected rows during INSERT and UPDATE operations. During an INSERT operation, it holds the new rows being added to the table. In an UPDATE operation, it contains the new values post-update.
- The DELETED table, on the other hand, stores the affected rows during DELETE and UPDATE operations. In a DELETE operation, it contains the rows being removed from the table. For an UPDATE operation, it holds the old values before the update.
Example Logging Changes
Suppose we have an EmployeesDetails table and we want to create a trigger that logs all changes (inserts, updates, and deletes) to an EmployeesDetails _Log table.
SQL Script
CREATE TABLE EmployeesDetails (
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(100),
Position NVARCHAR(100),
Salary DECIMAL(10, 2)
);
CREATE TABLE EmployeesDetails_Audit (
AuditID INT IDENTITY(1,1) PRIMARY KEY,
EmployeeID INT,
Name NVARCHAR(100),
Position NVARCHAR(100),
Salary DECIMAL(10, 2),
ChangeDate DATETIME DEFAULT GETDATE(),
ChangeType NVARCHAR(10)
);
CREATE TRIGGER trgEmployeesDetailsAudit
ON EmployeesDetails
AFTER INSERT, UPDATE, DELETE
AS
BEGIN
IF EXISTS (SELECT * FROM inserted)
BEGIN
INSERT INTO EmployeesDetails_Audit (EmployeeID, Name, Position, Salary, ChangeType)
SELECT EmployeeID, Name, Position, Salary, 'INSERT'
FROM inserted;
END
IF EXISTS (SELECT * FROM deleted)
BEGIN
INSERT INTO EmployeesDetails_Audit (EmployeeID, Name, Position, Salary, ChangeType)
SELECT EmployeeID, Name, Position, Salary, 'DELETE'
FROM deleted;
END
END;
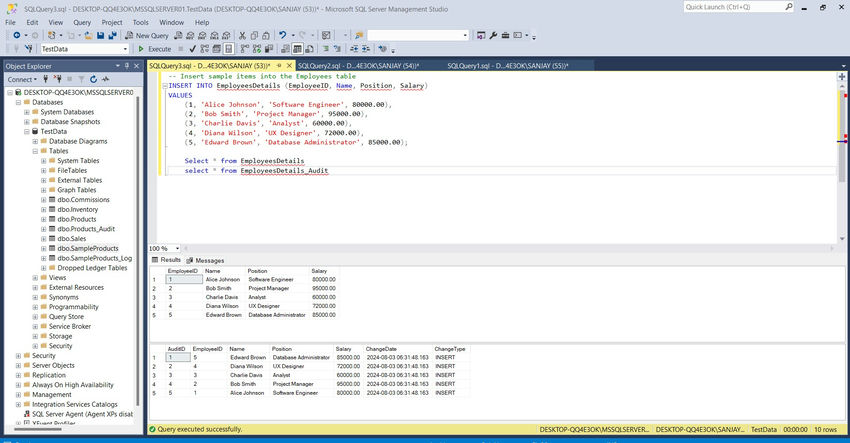
-- Insert sample items into the EmployeesDetails table
INSERT INTO EmployeesDetails (EmployeeID, Name, Position, Salary)
VALUES
(1, 'Alice Johnson', 'Software Engineer', 80000.00),
(2, 'Bob Smith', 'Project Manager', 95000.00),
(3, 'Charlie Davis', 'Analyst', 60000.00),
(4, 'Diana Wilson', 'UX Designer', 72000.00),
(5, 'Edward Brown', 'Database Administrator', 85000.00);
SELECT * FROM EmployeesDetails;
SELECT * FROM EmployeesDetails_Audit;
Query Window
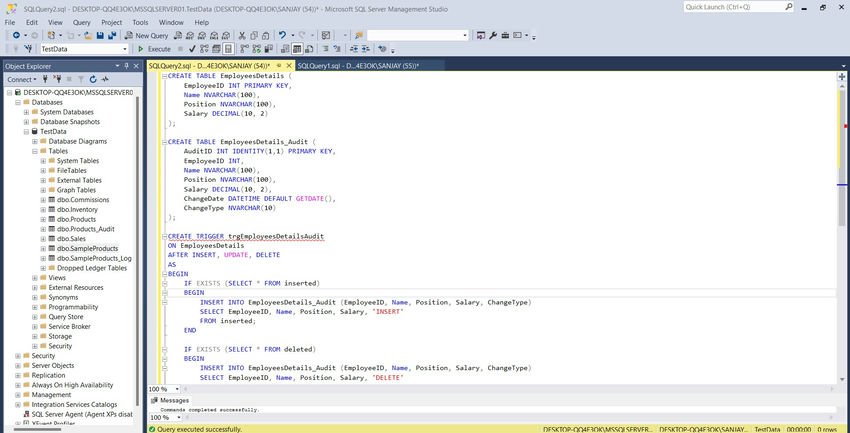
Execution of trigger
HostForLIFE.eu SQL Server 2022 Hosting
HostForLIFE.eu is European Windows Hosting Provider which focuses on Windows Platform only. We deliver on-demand hosting solutions including Shared hosting, Reseller Hosting, Cloud Hosting, Dedicated Servers, and IT as a Service for companies of all sizes.
