Frequently, systems utilize distributed databases containing distributed tables. Multiple mechanisms facilitate distribution, including replication. In this situation, it is essential to continuously maintain the synchronization of a specific data segment. Additionally, it is necessary to verify the synchronization itself. This is when it becomes necessary to compare data in two tables.
Before contrasting data in two tables, you must ensure that their schemas are either identical or distinguishable in an acceptable manner. Acceptably distinct refers to a difference in the definition of two tables that enables correct data comparison. For example, types of corresponding columns of compared tables must be mapped without data loss.
Compare the SQL Server schemas of the two Employee tables from the JobEmpl and JobEmplDB databases.
For further work, it is necessary to review the Employee table definitions in the JobEmpl and JobEmplDB databases:
USE [JobEmpl]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Employee](
[EmployeeID] [int] IDENTITY(1,1) NOT NULL,
[FirstName] [nvarchar](255) NOT NULL,
[LastName] [nvarchar](255) NOT NULL,
[Address] [nvarchar](max) NULL,
[CheckSumVal] AS (checksum((coalesce(CONVERT([nvarchar](max),[FirstName]),N'')+coalesce(CONVERT([nvarchar](max),[LastName]),N''))+coalesce(CONVERT([nvarchar](max),[Address]),N''))),
[REPL_GUID] [uniqueidentifier] ROWGUIDCOL NOT NULL,
CONSTRAINT [PK_Employee_EmployeeID] PRIMARY KEY CLUSTERED
(
[EmployeeID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 80) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
ALTER TABLE [dbo].[Employee] ADD CONSTRAINT [Employee_DEF_REPL_GUID] DEFAULT (newsequentialid()) FOR [REPL_GUID]
GO
//and
USE [JobEmplDB]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Employee](
[EmployeeID] [int] IDENTITY(1,1) NOT NULL,
[FirstName] [nvarchar](255) NOT NULL,
[LastName] [nvarchar](255) NOT NULL,
[Address] [nvarchar](max) NULL,
CONSTRAINT [PK_Employee_EmployeeID] PRIMARY KEY CLUSTERED
(
[EmployeeID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
Comparing Database Schemas using SQL Server Data Tools
With the help of Visual Studio and SSDT, you can compare database schemas. To do this, you need to create a new project “JobEmployee” by doing the following:
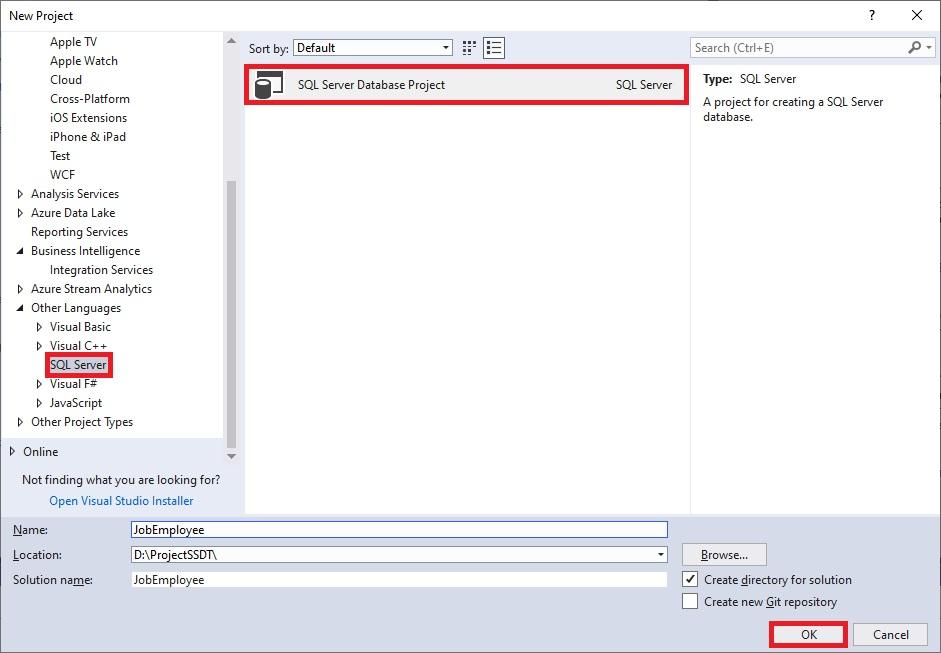
Then you need to import the database.
To do this, right-click the project and in the context menu, select Import \ Database..:
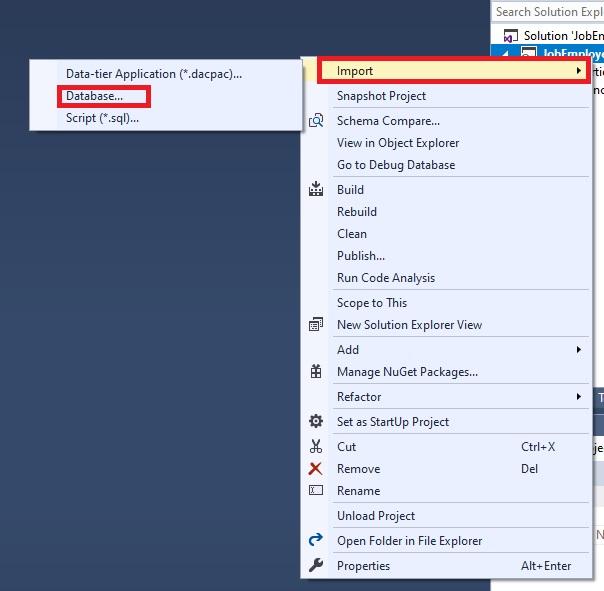
Next, hit the “Select connection…” button and in the cascading menu, in the “Browse” tab set up the connection to JobEmpl database as follows:

Next, click the “Start” button to start the import of the JobEmpl database:
You will then see a window showing the progress of the database import:
When the database import process is completed, press “Finish”:
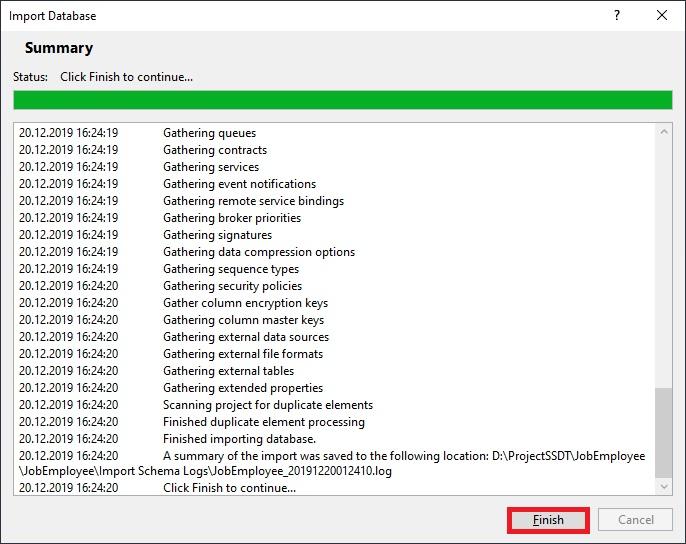
Once it is finished, JobEmployee project will contain directories, subdirectories, and database objects definitions in the following form:
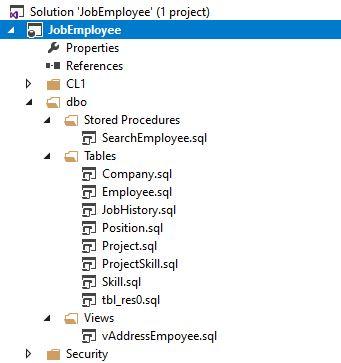
Once it is finished, JobEmployee project will contain directories, subdirectories, and database objects definitions in the following form:
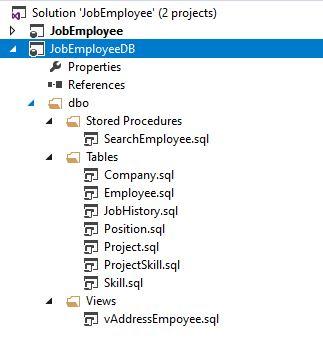
In the same way, we create a similar JobEmployeeDB project and import JobEmplDB database into it:
Now, right-click the JobEmployee project and in the drop-down menu, select “Schema Compare”:
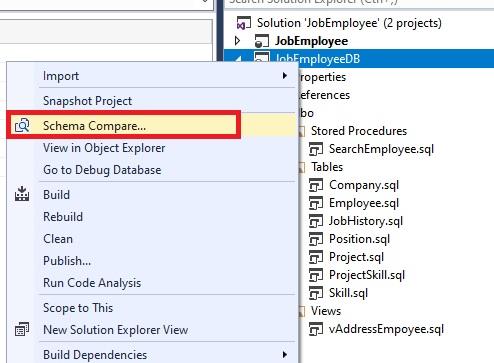
This will bring up the database schema compare window.
In the window, you need to select the projects as source and target, and then click the “Compare” button to start the comparison process:
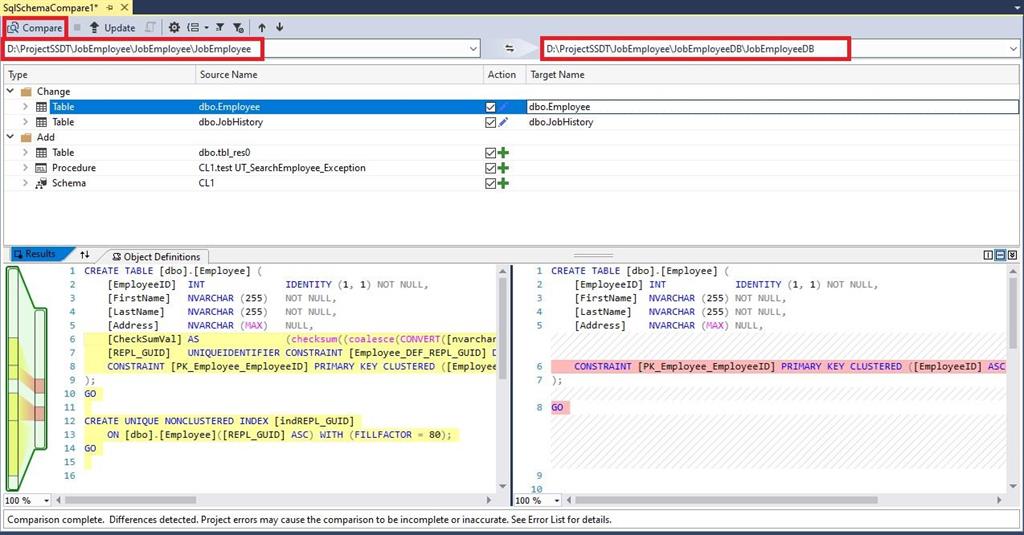
We can see here that despite the differences between the definitions of the Employee tables in two databases, the table columns that we need for comparison are identical in data type. This means that the difference in the schemas of the Employee tables is acceptable. That is, we can compare the data in these two tables.
We can also use other tools to compare database schemas such as dbForge Schema Compare for SQL Server.
Comparing database schemas with the help of dbForge Schema Compare
Now, to compare database table schemas, we use a tool dbForge Schema Compare for SQL Server, which is also included in SQL Tools.
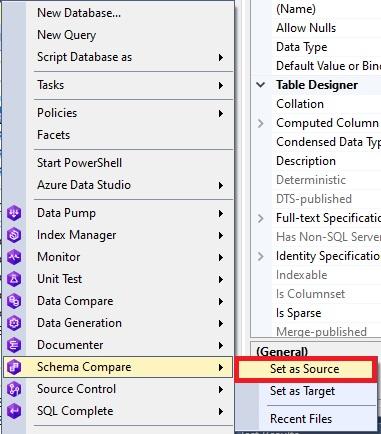
For this, in SSMS, right-click the first database and in the drop-down menu, select Schema Compare\ Set as Source:
We simply transfer JobEmplDB, the second database, to Target area and click the green arrow between source and target:
You simply need to press the “Next” button in the opened database schema comparison project:
Leave the following settings at their defaults and click the “Next” button:
In the “Schema Mapping” tab, we also leave everything by default and press the “Next” button:
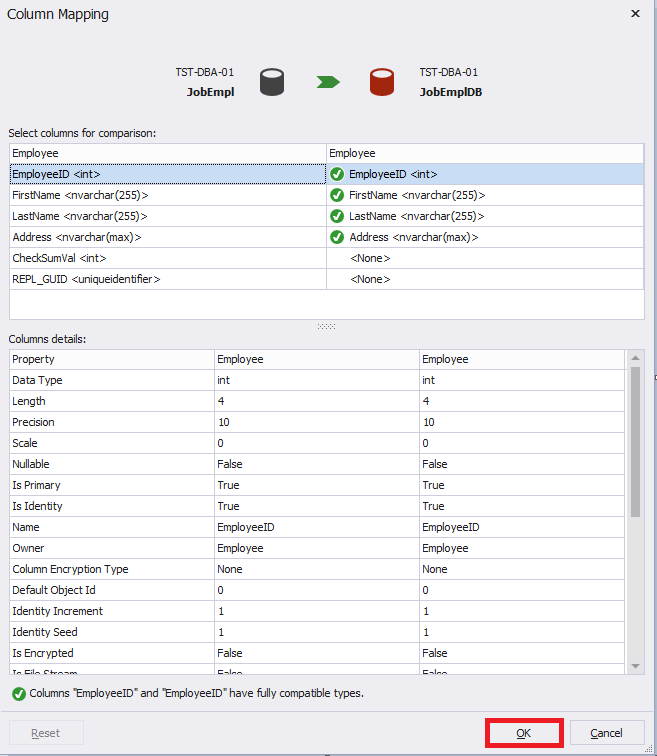
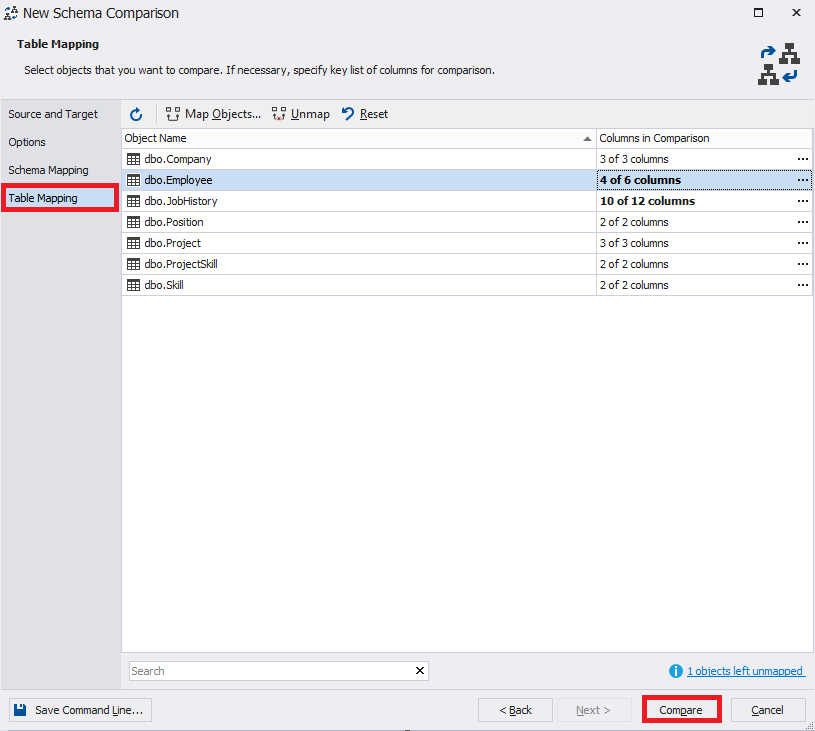
On the “Table Mapping” tab, select the required Employee table and on the right of the table name, click the ellipsis:
The table mapping window opens up:
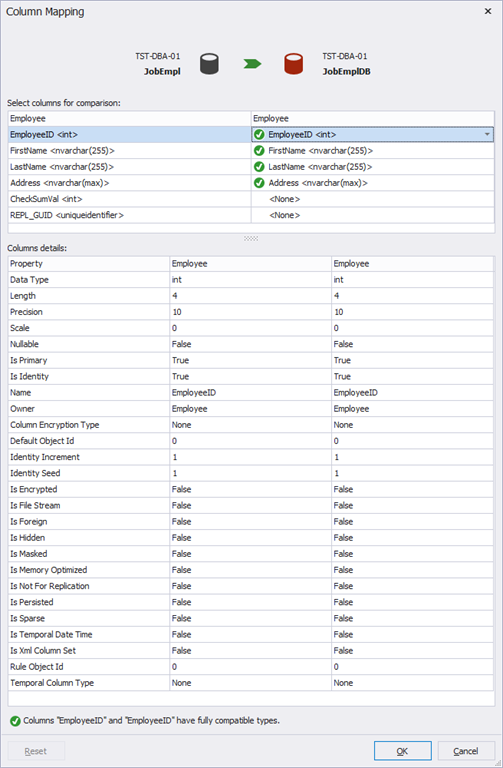
In our case, only 4 fields are mapped, because two last fields are contained only in the JobEmpl database and are absent in the JobEmplDB database.
This setting is useful when column names in the source table and target table do not match.
The “Column details” table displays the column definition details in two tables: on the left – from the source database and on the right – from the target database.
Now hit the “OK” button
Now, to start the database schema comparison process, click the “Compare” button:
A progress bar will appear
We then select the desired Employee table.
At the bottom left, you can see the code for defining the source database table and on the right – the target database table.
We can see here, as before, that the definitions of the Employee table in two databases JobEmpl and JobEmplDB show admissible distinction, that is why we can compare data in these two tables.
Let us now move on to the comparison of the data in two tables itself.
Comparing database data using SSIS
Let’s first make a comparison using SSIS. For this, you need to have SSDT installed.
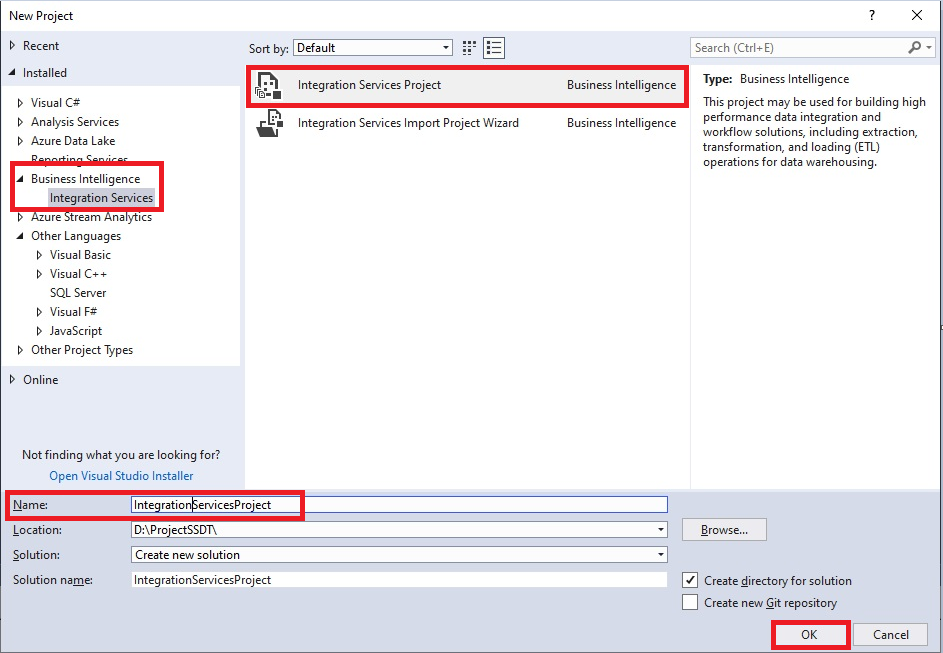
We create a project called Integration Service Project in Visual Studio and name it IntegrationServicesProject
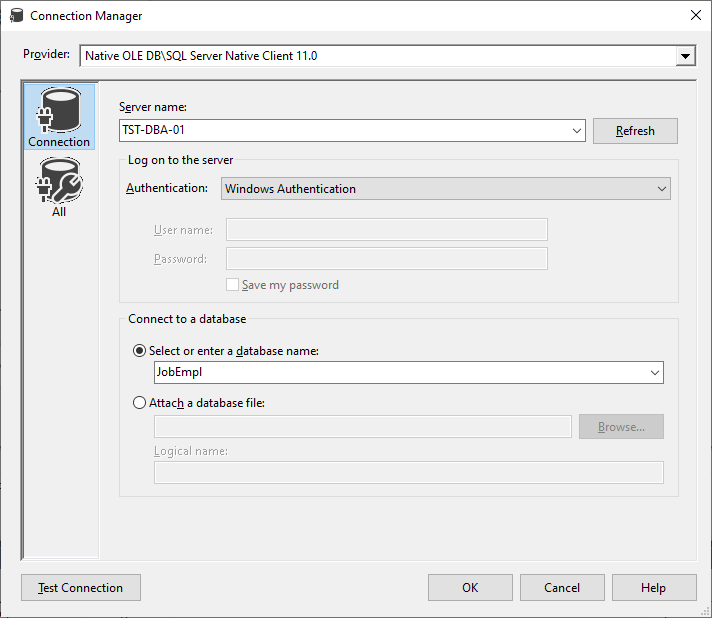
We then create three connections:
To the source JobEmpl database
To the target JobEmplDB database
To the JobEmplDiff database, where the table of differences will be displayed the following way below:
That way, new connections will be displayed in the project.
Then, in the project, in the “Control Flow” tab, we create a data flow task and name it “data flow task”
Let us now switch to the data flow and create an element “Source OLE DB” by doing the following
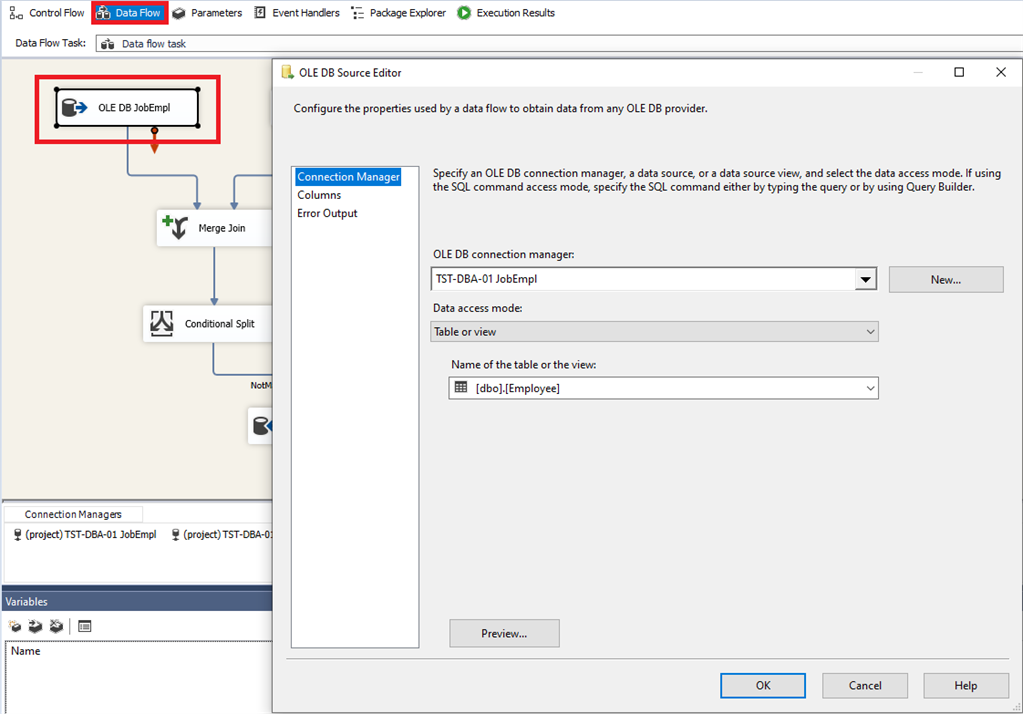
On the “Columns” tab, we then select the fields required for comparison
And now, right-click the created data source and in the drop-down menu, select “Show Advanced Editor…”
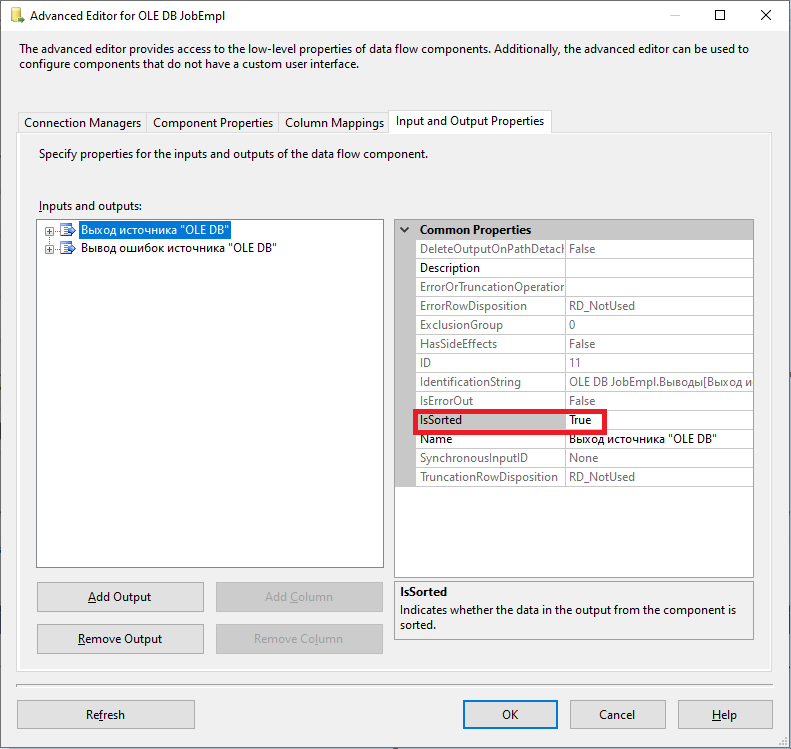
Next, for each of the “Output Columns” groups for the EpmloyeeID column, set SortKeyPosition property to 1. That is, we sort by the EmployeeID field value in ascending order,
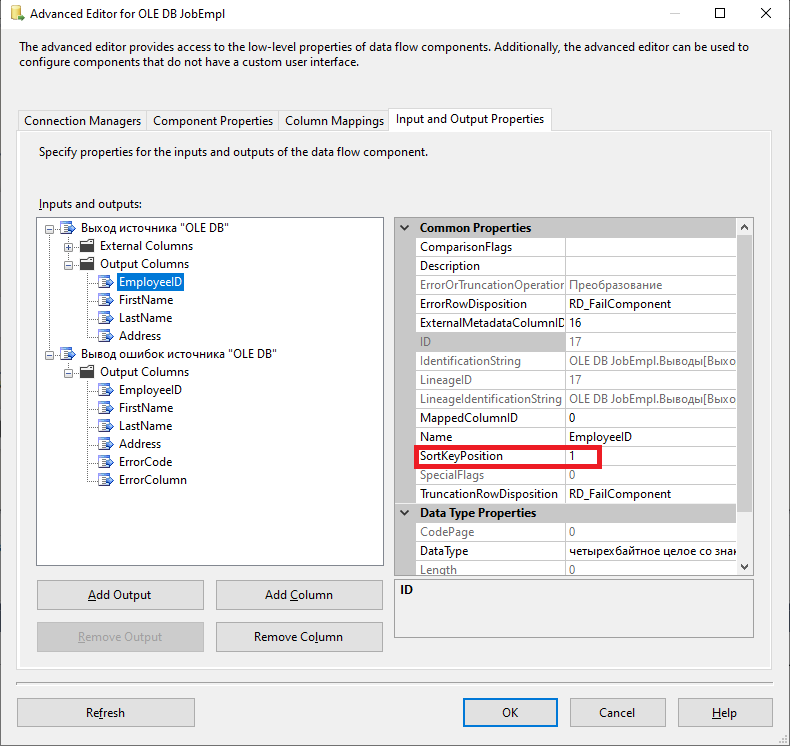
Similarly, let us create and set the data source to the JobEmplDB database.
That way, we obtain two created sources in the data flow task
Now, we create a merge join element in the following way:
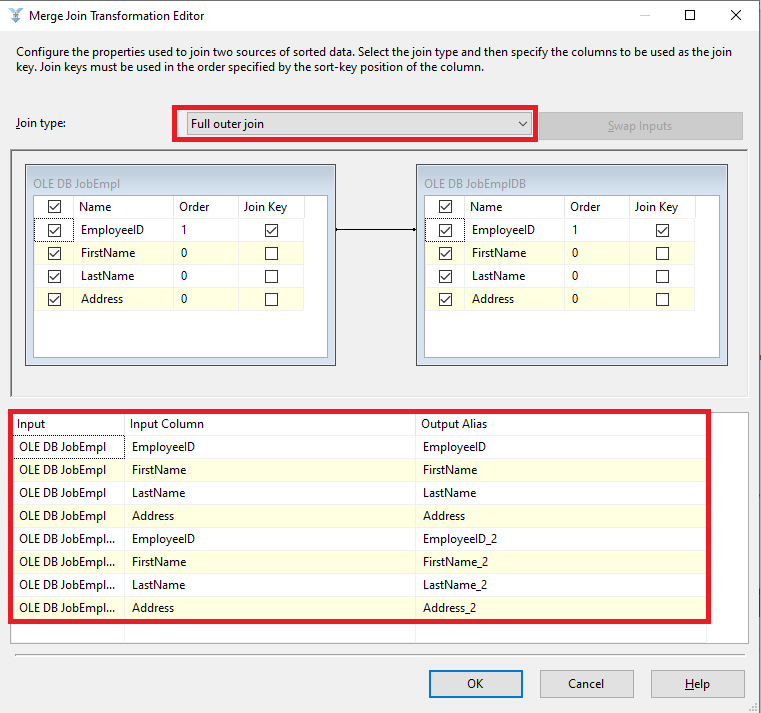
Please note that we merge tables using a full outer join.
We then connect our sources to the created join element by merging “Merge Join”
We make the connection from JobEmpl left and the connection from JobEmplDB – right.
In fact, it is not that important, it is possible to do this the other way around.
In the JobEmplDiff database, we create a different table called EmployeeDiff, where we are going to put data differences in the following manner:
USE [JobEmplDiff]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[EmployeeDiff](
[ID] [int] IDENTITY(1,1) NOT NULL,
[EmployeeID] [int] NULL,
[EmployeeID_2] [int] NULL,
[FirstName] [nvarchar](255) NULL,
[FirstName_2] [nvarchar](255) NULL,
[LastName] [nvarchar](255) NULL,
[LastName_2] [nvarchar](255) NULL,
[Address] [nvarchar](max) NULL,
[Address_2] [nvarchar](max) NULL,
CONSTRAINT [PK_EmployeeDiff_1] PRIMARY KEY CLUSTERED
(
[ID] ASC
) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 80) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
Now, let us get back to our project and in the data flow task, we create a conditional split element
In the Conditional field for NotMatch, you need to type the following expression:
(
ISNULL(EmployeeID)
|| ISNULL(EmployeeID)
)
|| (
REPLACENULL(FirstName, "") != REPLACENULL(FirstName_2, "")
)
|| (
REPLACENULL(LastName, "") != REPLACENULL(LastName_2, "")
)
|| (
(
Address != Address_2
&& (!ISNULL(Address))
&& (!ISNULL(Address_2))
)
|| ISNULL(Address) != ISNULL(Address_2)
)
This expression is true if the fields do not match with account for NULL values for the same EmployeeID value. And it is true if there is no match for the EmployeeID value from one table for the EmployeeID value in the other table, that is, if there are no rows in both tables that have the EmployeeID value.
You can obtain a similar result in the form of selection using the following T-SQL query:
SELECT
e1.[EmployeeID] AS [EmployeeID],
e2.[EmployeeID] AS [EmployeeID_2],
e1.[FirstName] AS [FirstName],
e2.[FirstName] AS [FirstName_2],
e1.[LastName] AS [LastName],
e2.[LastName] AS [LastName_2],
e1.[Address] AS [Address],
e2.[Address] AS [Address_2]
FROM
[JobEmpl].[dbo].[Employee] AS e1
FULL OUTER JOIN [JobEmplDB].[dbo].[Employee] AS e2 ON e1.[EmployeeID] = e2.[EmployeeID]
WHERE
(e1.[EmployeeID] IS NULL)
OR (e2.[EmployeeID] IS NULL)
OR (COALESCE(e1.[FirstName], N'') <> COALESCE(e2.[FirstName], N''))
OR (COALESCE(e1.[LastName], N'') <> COALESCE(e2.[LastName], N''))
OR (COALESCE(e1.[Address], N'') <> COALESCE(e2.[Address], N''));
Now, let us connect the elements “Merge Join” and “Conditional Split”
Next, we create an OLE DB destination element.
Now, we map the columns.
We set “Error Output” tab by default.
We can now join “Conditional Split” and “OLE DB JobEmplDiff” elements. As a result, we get a complete data flow.
Let us run the package that we have obtained.
Upon successful completion of the package work, all its elements turn into green circles.
If an error occurs, it is displayed in the form of a red circle instead of a green one. To resolve any issues, you need to read the log files.
To analyze the data difference, we need to derive the necessary data from the EmployeeDiff table of the JobEmplDiff database:
SELECT
[ID],
[EmployeeID],
[EmployeeID_2],
[FirstName],
[FirstName_2],
[LastName],
[LastName_2],
[Address],
[Address_2]
FROM
[JobEmplDiff].[dbo].[EmployeeDiff]
Here, you can see the Employee table from JobEmpl database, where Address isn’t set, and FirstName and LastName are mixed up in some columns. However, there is a bunch of missing rows in JobEmplDB, which exist in JobEmpl.
HostForLIFE SQL Server 2019 Hosting
HostForLIFE is European Windows Hosting Provider which focuses on Windows Platform only. We deliver on-demand hosting solutions including Shared hosting, Reseller Hosting, Cloud Hosting, Dedicated Servers, and IT as a Service for companies of all sizes.
