In this article, we will learn how to create a database table in SQL Server using the SSIS package.
As we know, data is growing massively, and we need to have the capability to extract data from numerous sources such as Oracle, Excel files, and SQL Server databases. SSIS provides integration and workflow solutions through which we can connect with multiple sources. We can build inflow and outflow of data and build pipelines through SSIS packages.
In order to work on SSIS, you need to install Sql Server Data Tools (SSDT) and the Integration Service component. I have used the SSDT 2022 version.
Now, let’s explore more and learn how we can create a table in SQL Server using the SSIS package.
We need to follow below steps:
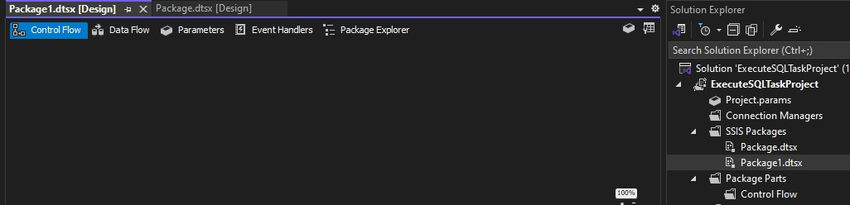
Step 1. Firstly, create a new SSIS package by right-clicking in Solution Explorer. A new SSIS Package1.dtsx is created, which we can see in the snippet below.
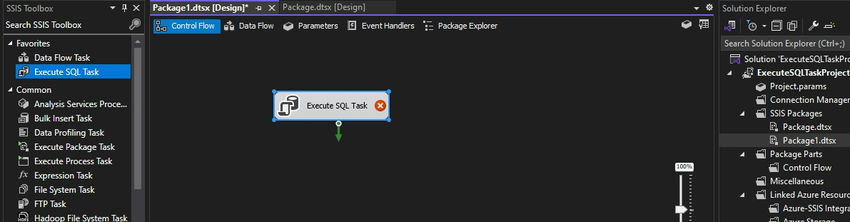
Step 2. Now go to the SSIS toolbox, select Execute SQL Task, and drag and drop it to the new SSIS package. Below is the snippet.
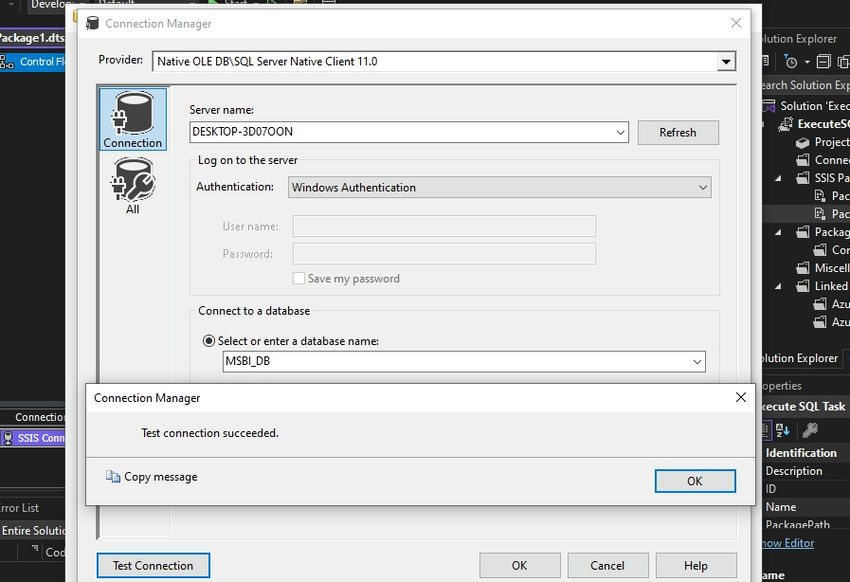
Step 3. Now, establish a new connection and make sure to test the connection.
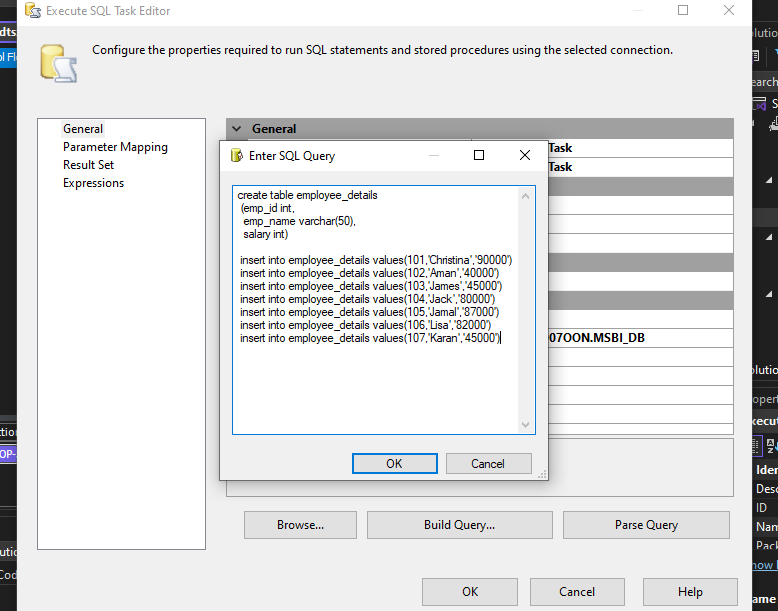
Step 4. Now consider the script below and put this in the SQLStatement section in the Task Editor.
create table employee_details
(emp_id int,
emp_name varchar(50),
salary int)
insert into employee_details values(101,'Christina','90000')
insert into employee_details values(102,'Aman','40000')
insert into employee_details values(103,'James','45000')
insert into employee_details values(104,'Jack','80000')
insert into employee_details values(105,'Jamal','87000')
insert into employee_details values(106,'Lisa','82000')
insert into employee_details values(107,'Karan','45000')
After establishing the connection and entering the script, we can see below the red mark is gone.
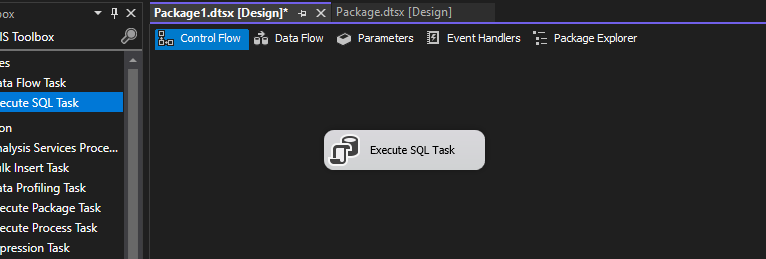
Step 5. Now, execute the package by hitting the start button.
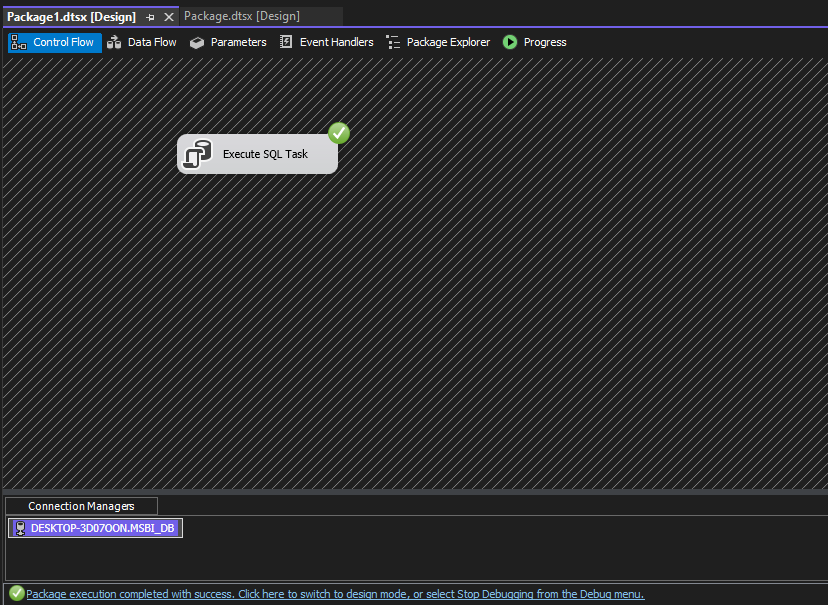
We can see in the above screenshot that the SQL task was executed successfully.
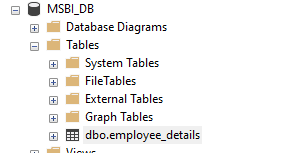
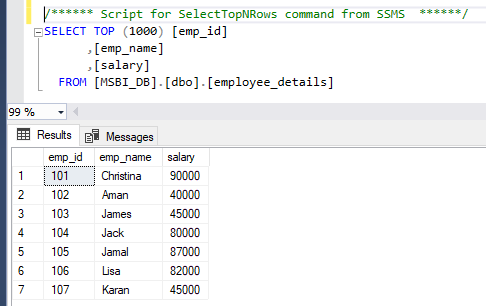
Step 6. Now, we will see in the SQL Server using SSMS that the employee_details table is created. Below is the screenshot.
Summary
You have learned today how to create a new table using the SSIS task. The benefit of using SSIS is automation since we can run packages either on-demand or using the scheduler. We can further extend this with the help of project parameters. I hope you liked the article. Please let me know your feedback/ suggestions in the comments section below.
HostForLIFE.eu SQL Server 2022 Hosting
HostForLIFE.eu is European Windows Hosting Provider which focuses on Windows Platform only. We deliver on-demand hosting solutions including Shared hosting, Reseller Hosting, Cloud Hosting, Dedicated Servers, and IT as a Service for companies of all sizes.
