Microsoft has included new features and improvements to SQL Server 2022 in order to boost functionality, usability, and speed. The DATE_BUCKET function is one of these new capabilities; it's a useful tool for developers and data professionals working with time-based data. The DATE_BUCKET function streamlines interval management and date grouping, facilitating the aggregation and analysis of time-based data over predetermined timeframes. For SQL developers, data engineers, and DBAs who regularly handle temporal data analysis, this is especially helpful.
Understanding the DATE_BUCKET Function
What is DATE_BUCKET?
The DATE_BUCKET function in SQL Server 2022 is designed to help group and truncate dates into fixed intervals (or "buckets"). This makes it easier to group data for analysis over consistent time periods such as days, weeks, months, quarters, or years. This is especially useful for reporting and data visualization when you want to group time-based data into periods like hourly or weekly aggregates.
DATE_BUCKET (datepart, number, date [, origin ] )
--datepart: The part of the date you want to group by, such as a day, week, month, etc. This can be
--number: The size of the time bucket, which must be an integer. year, month, week, day, hour, minute, second, millisecond, etc.
--date: The date to be truncated and grouped by the interval and datepart.
Return Type
The function returns a date/time value that is rounded down to the start of the specified bucket. This allows for grouping time-based data into logical intervals.
How is DATE_BUCKET Different from Other T-SQL Functions?
Other T-SQL functions, like DATEADD, DATEDIFF, and DATEPART, are typically used to manipulate dates, extract parts of dates, or compute the difference between dates. However, these functions don't natively support the concept of fixed time intervals (buckets). DATE_BUCKET, on the other hand, allows for grouping dates into regular intervals, which can be critical for generating time-based reports.
Example 1. Month Interval Example
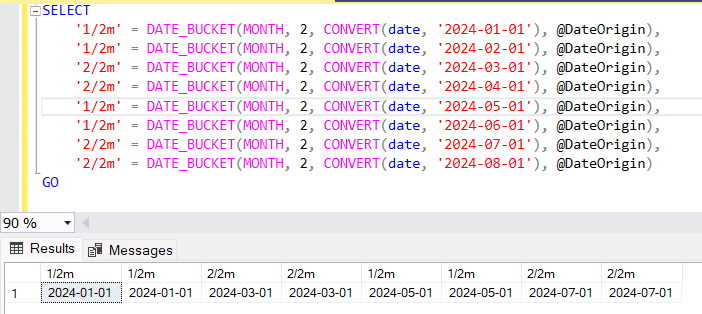
This example groups dates into 2-month intervals, starting from January 1, 2024.
DECLARE @DateOrigin date = '2024-01-01'
SELECT
'1/2m' = DATE_BUCKET(MONTH, 2, CONVERT(date, '2024-01-01'), @DateOrigin),
'1/2m' = DATE_BUCKET(MONTH, 2, CONVERT(date, '2024-02-01'), @DateOrigin),
'2/2m' = DATE_BUCKET(MONTH, 2, CONVERT(date, '2024-03-01'), @DateOrigin),
'2/2m' = DATE_BUCKET(MONTH, 2, CONVERT(date, '2024-04-01'), @DateOrigin),
'1/2m' = DATE_BUCKET(MONTH, 2, CONVERT(date, '2024-05-01'), @DateOrigin),
'1/2m' = DATE_BUCKET(MONTH, 2, CONVERT(date, '2024-06-01'), @DateOrigin),
'2/2m' = DATE_BUCKET(MONTH, 2, CONVERT(date, '2024-07-01'), @DateOrigin),
'2/2m' = DATE_BUCKET(MONTH, 2, CONVERT(date, '2024-08-01'), @DateOrigin)
GO
Output
Example 2. Week Interval Example
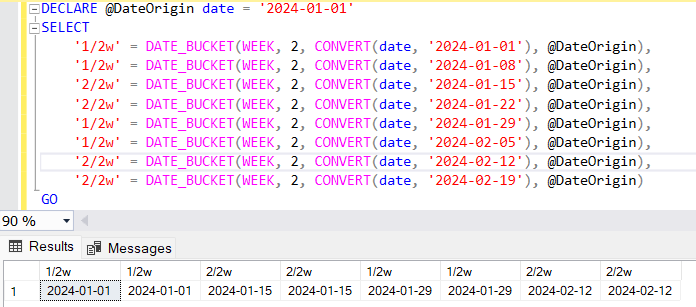
This example groups dates into 2-week intervals, starting from January 1, 2024.
DECLARE @DateOrigin date = '2024-01-01'
SELECT
'1/2w' = DATE_BUCKET(WEEK, 2, CONVERT(date, '2024-01-01'), @DateOrigin),
'1/2w' = DATE_BUCKET(WEEK, 2, CONVERT(date, '2024-01-08'), @DateOrigin),
'2/2w' = DATE_BUCKET(WEEK, 2, CONVERT(date, '2024-01-15'), @DateOrigin),
'2/2w' = DATE_BUCKET(WEEK, 2, CONVERT(date, '2024-01-22'), @DateOrigin),
'1/2w' = DATE_BUCKET(WEEK, 2, CONVERT(date, '2024-01-29'), @DateOrigin),
'1/2w' = DATE_BUCKET(WEEK, 2, CONVERT(date, '2024-02-05'), @DateOrigin),
'2/2w' = DATE_BUCKET(WEEK, 2, CONVERT(date, '2024-02-12'), @DateOrigin),
'2/2w' = DATE_BUCKET(WEEK, 2, CONVERT(date, '2024-02-19'), @DateOrigin)
GO
Output
Example 3. Day Interval Example
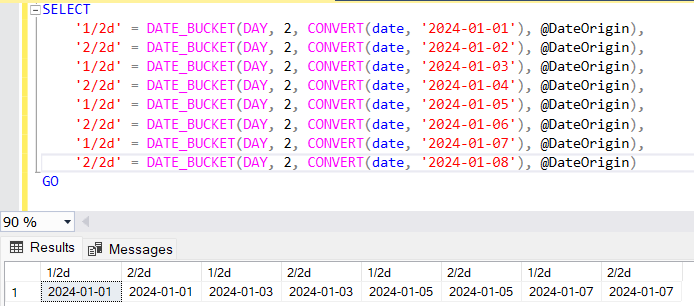
This example groups dates into 2-day intervals, starting from January 1, 2022.
DECLARE @DateOrigin date = '2024-01-01'
SELECT
'1/2d' = DATE_BUCKET(DAY, 2, CONVERT(date, '2024-01-01'), @DateOrigin),
'2/2d' = DATE_BUCKET(DAY, 2, CONVERT(date, '2024-01-02'), @DateOrigin),
'1/2d' = DATE_BUCKET(DAY, 2, CONVERT(date, '2024-01-03'), @DateOrigin),
'2/2d' = DATE_BUCKET(DAY, 2, CONVERT(date, '2024-01-04'), @DateOrigin),
'1/2d' = DATE_BUCKET(DAY, 2, CONVERT(date, '2024-01-05'), @DateOrigin),
'2/2d' = DATE_BUCKET(DAY, 2, CONVERT(date, '2024-01-06'), @DateOrigin),
'1/2d' = DATE_BUCKET(DAY, 2, CONVERT(date, '2024-01-07'), @DateOrigin),
'2/2d' = DATE_BUCKET(DAY, 2, CONVERT(date, '2024-01-08'), @DateOrigin)
GO
Output
Use Cases
1. Grouping Sales Data by Weekly Buckets
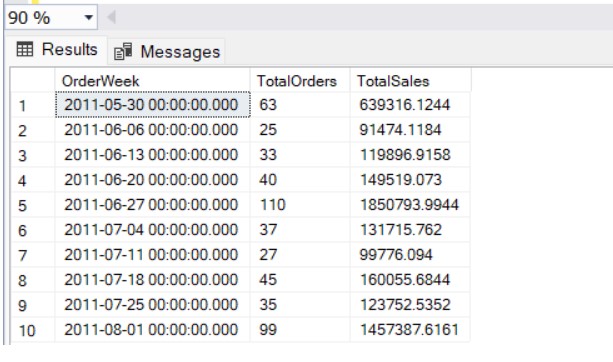
Suppose we want to analyze sales orders in AdventureWorks2022 and group the orders into weekly intervals. Using DATE_BUCKET, we can easily create these weekly buckets based on the OrderDate from the Sales.SalesOrderHeader table.
In this query
DATE_BUCKET(1, WEEK, OrderDate) groups the sales orders into weekly buckets, starting from the earliest OrderDate.
The query aggregates the total number of orders and the total sales (TotalDue) within each week.
USE AdventureWorks2022
GO
SELECT
DATE_BUCKET(WEEK, 1, OrderDate) AS OrderWeek,
COUNT(SalesOrderID) AS TotalOrders,
SUM(TotalDue) AS TotalSales
FROM
Sales.SalesOrderHeader
GROUP BY
DATE_BUCKET(WEEK, 1, OrderDate)
ORDER BY
OrderWeek
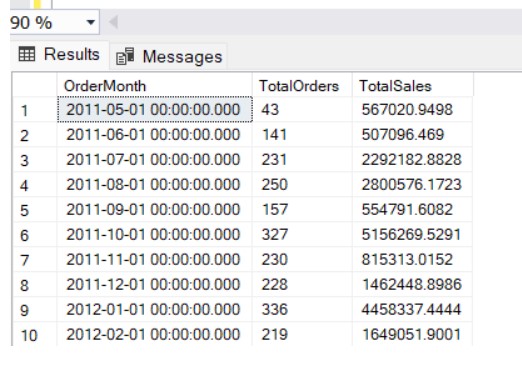
2. Monthly Sales Data Analysis
For longer-term trends, we may want to aggregate sales on a monthly basis. DATE_BUCKET makes it simple to group the data into months, just as easily as weeks.
Example: Monthly Sales Performance
This query aggregates the sales orders into monthly intervals using DATE_BUCKET(1, MONTH, OrderDate). You can easily visualize this data in a line graph or bar chart to track monthly sales performance over time.
USE AdventureWorks2022
GO
SELECT
DATE_BUCKET(MONTH, 1, OrderDate) AS OrderMonth,
COUNT(SalesOrderID) AS TotalOrders,
SUM(TotalDue) AS TotalSales
FROM
Sales.SalesOrderHeader
GROUP BY
DATE_BUCKET(MONTH, 1, OrderDate)
ORDER BY
OrderMonth
Output
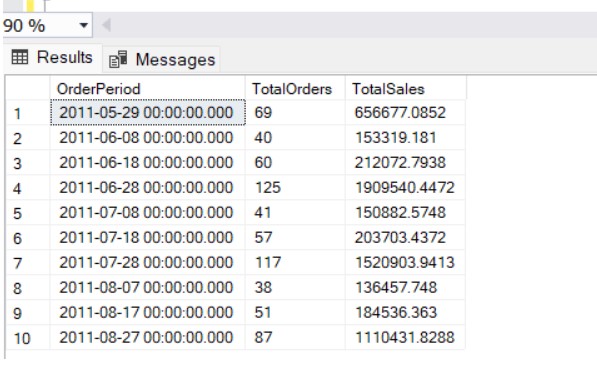
3. Grouping Data in Custom Intervals (e.g., 10-Day Buckets)
While DATE_BUCKET allows for standard intervals like weeks or months, you can also group dates into custom intervals. For instance, if you want to create a report based on 10-day periods instead of full months or weeks, DATE_BUCKET can handle that too.
Here, we specify an interval of 10 days, and the sales orders are grouped into periods based on that interval. This can be useful in scenarios where typical calendar boundaries like weeks or months are too coarse or too fine.
USE AdventureWorks2022
GO
SELECT
DATE_BUCKET(DAY, 10, OrderDate) AS OrderPeriod,
COUNT(SalesOrderID) AS TotalOrders,
SUM(TotalDue) AS TotalSales
FROM
Sales.SalesOrderHeader
GROUP BY
DATE_BUCKET(DAY, 10, OrderDate)
ORDER BY
OrderPeriod
Output
Comparing DATE_BUCKET to Other Functions
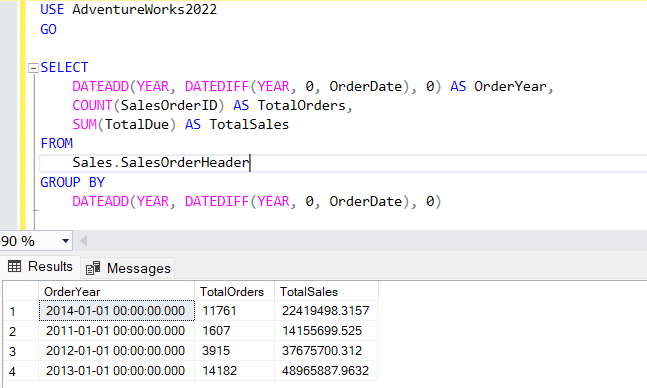
1. DATEADD and DATEDIFF
In the past, SQL developers would use combinations of DATEADD and DATEDIFF to group dates into intervals. For example, you could group sales data by year with these functions:
While this method works, it is less intuitive and more cumbersome than using DATE_BUCKET, which allows for direct and flexible interval grouping.
USE AdventureWorks2022
GO
SELECT
DATEADD(YEAR, DATEDIFF(YEAR, 0, OrderDate), 0) AS OrderYear,
COUNT(SalesOrderID) AS TotalOrders,
SUM(TotalDue) AS TotalSales
FROM
Sales.SalesOrderHeader
GROUP BY
DATEADD(YEAR, DATEDIFF(YEAR, 0, OrderDate), 0)
Output
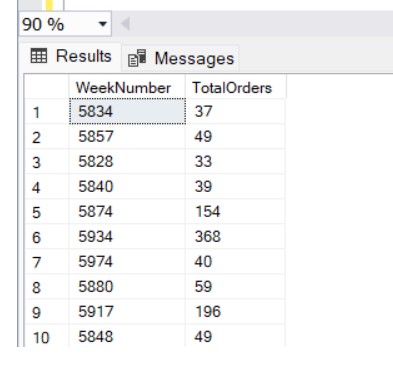
2. FLOOR or CEILING on Date Calculations
Another workaround for bucketing dates was using FLOOR or CEILING in conjunction with date calculations. While effective, this approach was error-prone and harder to maintain.
For example, to group dates into weekly intervals using FLOOR, you might write something like this:
This code is not as readable as using DATE_BUCKET. The DATE_BUCKET function simplifies and abstracts away the complexity, making it easier to reason about your queries.
USE AdventureWorks2022
GO
SELECT
FLOOR(DATEDIFF(DAY, '1900-01-01', OrderDate) / 7) AS WeekNumber,
COUNT(SalesOrderID) AS TotalOrders
FROM
Sales.SalesOrderHeader
GROUP BY
FLOOR(DATEDIFF(DAY, '1900-01-01', OrderDate) / 7)
Output
Benefits of Using DATE_BUCKET
1. Simplified Code
One of the most apparent benefits of DATE_BUCKET is the simplification of code when compared to older methods of date bucketing. Instead of using complex expressions with DATEADD and DATEDIFF, you can now achieve the same result with a single, readable function.
2. Flexibility and Power
DATE_BUCKET provides a powerful tool for aggregating time-based data in flexible ways. Whether you need to group data by week, month, or even custom intervals like ten days or 15 minutes, DATE_BUCKET makes it easy to express and execute these groupings.
3. Improved Performance
By natively supporting time-based intervals in a straightforward function, DATE_BUCKET improves performance over workarounds that rely on complex date manipulation functions such as combinations of DATEADD, DATEDIFF, and FLOOR. These traditional approaches often require multiple calculations and transformations to achieve similar results, which can increase both complexity and computational overhead.
Conclusion
The introduction of the DATE_BUCKET function in SQL Server 2022 marks a significant enhancement for SQL developers, data engineers, and DBAs who frequently work with time-based data. By simplifying the process of grouping dates into consistent intervals, DATE_BUCKET not only makes queries more readable and easier to maintain but also improves performance by reducing reliance on complex, manual date manipulation functions. With its ability to streamline queries, improve code maintainability, and optimize performance, DATE_BUCKET represents a valuable addition to the SQL Server toolkit, empowering professionals to better manage and analyze their time-series data.
HostForLIFE.eu SQL Server 2022 Hosting
HostForLIFE.eu is European Windows Hosting Provider which focuses on Windows Platform only. We deliver on-demand hosting solutions including Shared hosting, Reseller Hosting, Cloud Hosting, Dedicated Servers, and IT as a Service for companies of all sizes.
