Today, I'm gonna show you how to sort numbers in SQL Server. It's not a difficult task but not an easy way. In the front end are many functions that for sorting values but SQL Server has no predefined function available.
For example I will sort the numbers 12,5,8,64,548,987,6542,4,285,11,26. SQL Server has no array list or array so how can we hold the values after sorting the numbers? SQL Server has temporary tables. Temporary automatically creates and drops the table after the execution.
First of all, create a temporary table. Suppose a problem occurs in SQL Server or during program execution. A Temporary table can't be deleted or dropped the proper way. When we want to create a table a second time a confirm error occurs as in the following:
There is already an object named '#temp' in the database.
So this type of problem is avoided by checking first if the table exists like this:
IF EXISTS (SELECT * FROM sys.tables
WHERE name = N'#temp' AND type = 'U') --check the #temp already exists in database or not
--Not:- type U stand for user
begin
drop table #temp
end
If the table already exists in the database then drop the table #temp.
My values are 12,5,8,64,548,987,6542,4,285,11,26. They need to be be split up before the sort. How can we split the numbers? Of course we can at the comma (,). If I split the at the comma then I get the numbers like this: 12 5 8 64 548 and so on. One question then arises is, how to split the value? Don't worry, I have done that.
select left('12,45,18,95',
CHARINDEX(',','12,45,18,95')-1))
If i run this query it should be return the value is 12
After that everything is fine, we get the value from the #temp table.
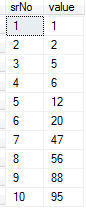
select ROW_NUMBER() over (order by value) 'srNo', value from #temp order by value
The following is a complete Stored Procedure to sort the numbers.
ALTER proc [dbo].[Porc_sortnumber]
as
begin
DECLARE @value VARCHAR(MAX)='1,2,5,6,12,88,47,95,56,20'
declare @lenth int =1
IF EXISTS (SELECT * FROM sys.tables
WHERE name = N'#temp' AND type = 'U') --check the #temp allready exists in database or not
--Not:- type U stand for user
begin
drop table #temp
end
create table #temp (id int identity(1,1),value int)
while(@lenth!=0 )
begin
insert into #temp(value) values(left(@value,(CHARINDEX(',',@value)-1)))
set @value= right(@value,len(@value)-((CHARINDEX(',',@value))))
set @lenth=CHARINDEX(',',@value)
end
insert into #temp(value) values(@value)
select ROW_NUMBER() over (order by value) 'srNo', value from #temp order by value
end
Output
I hope this article will helpful!
HostForLIFE.eu SQL Server 2014 Hosting
