I am pretty sure that all of us read or even participated in quite a few heated discussions about Common Language Runtime (CLR) code in Microsoft SQL Server. Some people state that CLR code works faster than T-SQL, others oppose them. Although, as with the other SQL Server technologies, there is no simple answer to that question. Both technologies are different in nature and should be used for the different tasks. T-SQL is the interpreted language, which is optimized for set-based logic and data access. CLR, on the other hand, produces compiled code that works the best for imperative procedural-style code.
Even with imperative code, we need to decide if we want to implement it in CLR or as the client-side code, perhaps running on the application servers. CLR works within SQL Server process. While, on one hand, it eliminates network traffic and can provide us the best performance due to the “closeness” to the data, CLR adds the load to the SQL Server. It is usually easier and cheaper to scale out application servers rather than upgrading SQL Server box.
There are some cases when we must use CLR code though. For example, let’s think about the queries that performing RegEx evaluations as part of the where clause. It would be inefficient to move such evaluations to the client code and there is no regular expressions support in SQL Server. So CLR is the only choice we have. Although, in the other cases, when procedural-style logic can be moved to the application servers, we should consider such option. Especially when application servers are residing closely to SQL Server and network latency and throughput are not an issue.
Today we will compare performance of the few different areas of CLR and T-SQL. I am not trying to answer the question – “what technology is better”. As usual it fits into “It depends” category. What I want to do is looking how technologies behave in the similar tasks when they can be interchanged.
Before we begin, let’s create the table and populate it with some data.
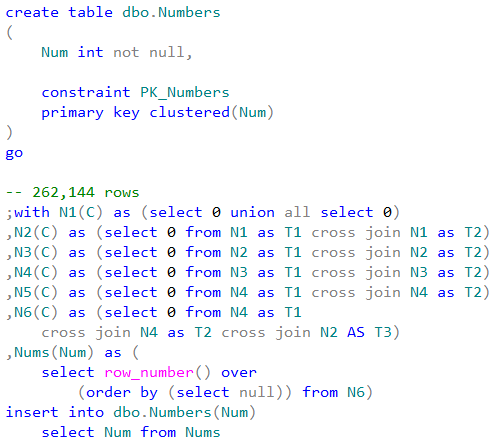
As the first step, let’s compare the user-defined functions invocation cost. We will use the simple function that accepts the integer value as the parameter and returns 1 in case if that value is even. We can see CLR C# implementation below.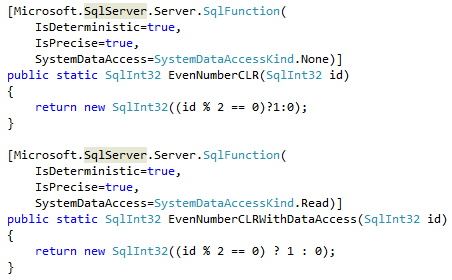
As we can see, there are the attributes specified for each function. Those attributes describes different aspects of UDF behavior and can help Query Optimizer to generate more efficient execution plans. I would recommend specifying them explicitly rather than relying on default values.
One of the attributes – DataAccess – indicates if function performs any data access. When this is the case, SQL Server calls the function in the different context that will allow access to the data. Setting up such context introduces additional overhead during the functional call, which we will see in a few minutes.
T-SQL implementation of those functions would look like that:

Let’s measure average execution time for the statements shown below. Obviously, different hardware leads to the different execution time although trends would be the same.
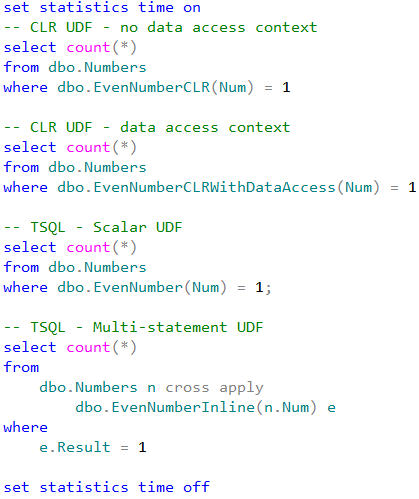
Each statement performs clustered index scan of dbo.Numbers table and checks if Num column is even for every row from the table. For CLR and T-SQL scalar user-defined functions, that introduces the actual function call. Inline multi-statement function, on the other hand, performed the calculation inline without function call overhead.
As we can see, CLR UDF without data access context performs about four times faster comparing to T-SQL scalar function. Even if establishing data-access context introduces additional overhead and increases execution time, it is still faster than T-SQL scalar UDF implementation.
The key point here though is than in such particular example the best performance could be achieved if we stop using the functions at all rather than converting T-SQL implementation to CLR UDF. Even with CLR UDF, the overhead of the function call is much higher than inline calculations.
Unfortunately, this is not always the case. While we should always think about code refactoring as the option, there are the cases when CLR implementation can outperform inline calculations even with all overhead it introduced. We are talking about mathematical calculations, string manipulations, XML parsing and serialization – to name just a few. Let’s test the performance of the functions that calculate the distance between two points defined by latitude and longitude.
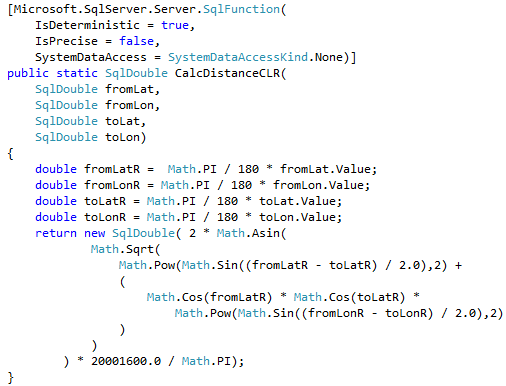

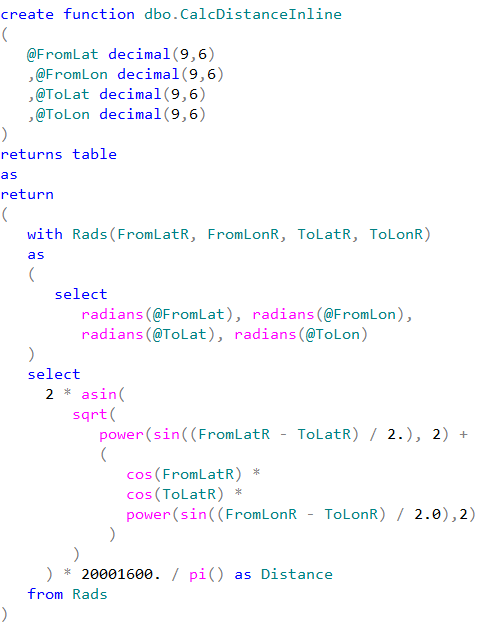


We can see that CLR UDF runs almost two times faster comparing to inline table-valued functions and more than five times faster comparing to T-SQL scalar UDF. Even with all calling overhead involved.
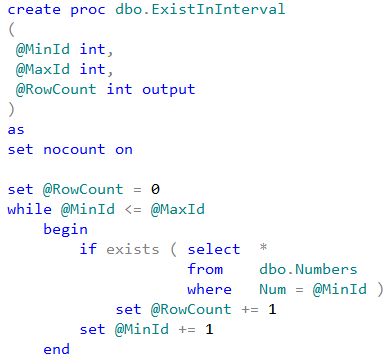
Now let’s look at the data access performance. The first test compares performance of the separate DML statements from T-SQL and CLR stored procedures. In that test we will create the procedures that calculate the number of the rows in dbo.Numbers table for specific Num interval provided as the parameters. We can see the implementation below

Table below shows the average execution time for stored procedure with the parameters that lead to 50,000 individual SELECT statements. As we can see, data access from CLR code is much less efficient and works about five times slower than data access from T-SQL.

Now let’s compare performance of the row-by-row processing using T-SQL cursor and .Net SqlDataReader class.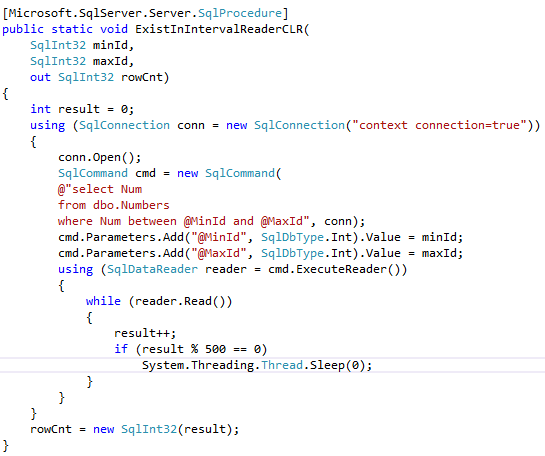
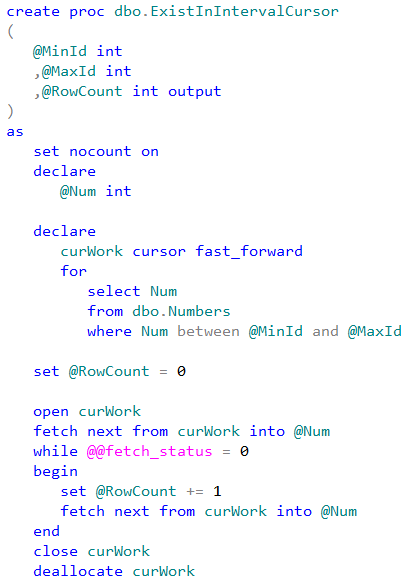
As we can see, SqlDataReader implementation is faster.

Finally, let’s look at the performance of CLR aggregates. We will use standard implementation of the aggregate that concatenates the values into comma-separated string.

As with user-defined functions, it is extremely important to set the attributes that tell Query Optimizer about CLR Aggregate behavior and implementation. This would help to generate more efficient execution plans and prevent incorrect results due to optimization. It is also important to specify MaxByteSize attribute that defines the maximum size of the aggregate output. In our case, we set it to -1 which means that aggregate could hold up to 2GB of data.
Speaking of T-SQL implementation, let’s look at the approach that uses SQL variable to hold intermediate results. That approach implements imperative row-by-row processing under the hood.
As another option let’s use FOR XML PATH technique. It is worth to mention that this technique could introduce different results by replacing XML special characters with character entities. For example, if our values contain < character, it would be replaced with < string.
Our test code would look like that:

When we compare the performance on the different row set sizes, we would see results below
As we can see, CLR aggregate has slightly higher startup cost comparing to T-SQL variable approach although it quickly disappears on the larger rowsets. Performance of both: CLR aggregate and FOR XML PATH methods linearly depend on the number of the rows to aggregate while performance of SQL Variable approach degrade exponentially. SQL Server needs to initiate the new instance of the string every time it concatenates the new value and it does not work efficiently especially when it needs to be populated with the large values.
The key point I would like to make with that example is that we always need to look at the options to replace imperative code with declarative set-based logic. While CLR usually outperforms procedural-style T-SQL code, set-based logic could outperform both of them.
While there are some cases when choice between technologies is obvious, there are the cases when it is not clear. Let us think about scalar UDF that needs to perform some data access. Lower invocation cost of CLR function can be mitigated by higher data access cost from there. Similarly, inline mathematical calculations in T-SQL could be slower than in CLR even with all invocation overhead involved. In those cases, we must test different approaches and find the best one which works in that particular case.
